Storing Texts as Semantic Graphs
A hobby project: to build a system that learns through conversation. I am playing with Discord.js to build Discord bot, SpaCy.io for NLP and Neo4j to build Knowledge Graphs.
In the process I am reading two great books:
a) Word Grammar by Richard Hudson
b) Graph-Powered Machine Learning by Alessandro Negro
1. Understanding the problem
What's the unknown?
How to store a text so that we can extract and generalise useful knowledge from it?
What's the data?
English texts of various lengths/topics etc. They are produced by real people and have the following linguistic structure:
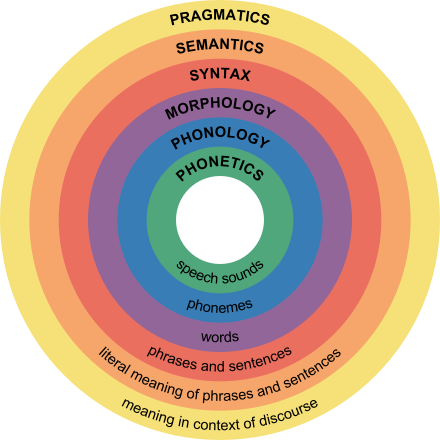
What's the condition?
The data architecture must make explicit:
- The temporal structure of the text
- The syntactic structure of the text
- Significant (meaningful) entities
- Relationships (aka meaning) among entities
2. Planning
The best way to expose relationships in a dataset is to build a graph out of them. This way we will be able to a) visualise the various structures that we want to expose and b) build the underlying data structures that we can traverse for our further analyses.
We will use Neo4j and write Cypher queries to test a simple example of a 4 sentence text stored as a graph.
3. Execution
Where do we start?
Let's start by exposing a simple temporal structure of the text.
Any text written from left-right, or in any other consistent fashion is conveying its linear temporal structure (sentence has a beginning and end and proceeds from the beginning to the end).
We will deal with purple "Morphology" level (ie words) first. This will give us the temporal structure.
What can we do?
We can make this linear structure explicit by storing text as a sequence of meaningful units (for us these are words and punctuation marks) using (Unit)-[:NEXT]->(Unit) graph.
Here is an example of a 4 sentence text stored as a graph that exposes its temporal structure. This graph shows that the text (blue node) has 4 sentences (pink nodes), each sentence has words (red nodes). Words are connected by temporal relationships.
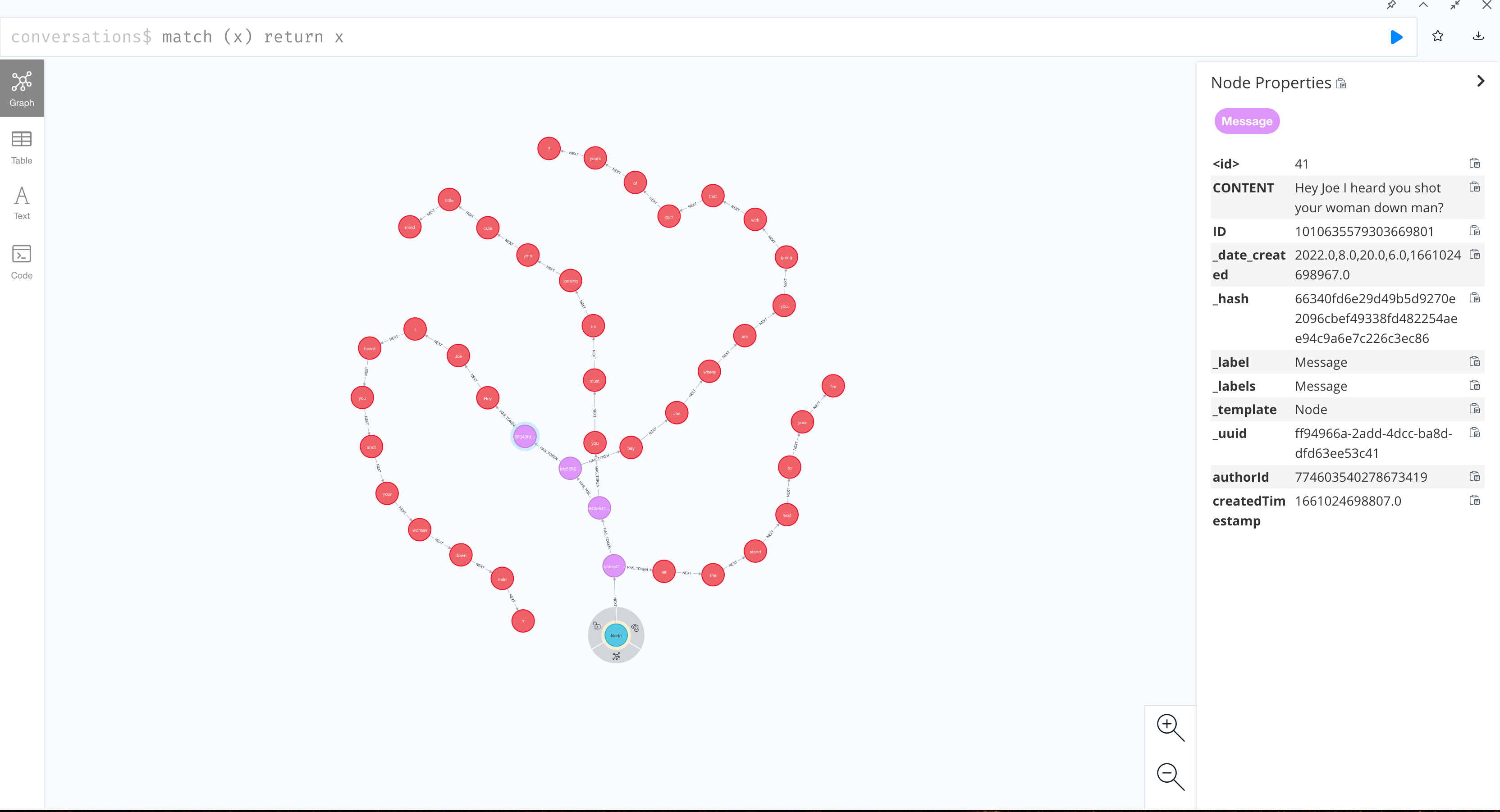
What do we gain by doing it?
By making temporal relationships explicit we will be able to:
- Check correctness of grammar
- Extract patterns
- Improve information search
- ...???
4. Revision
We managed to store a text as a sequence of sentences each containing a sequence of words and punctuation marks. We stored it as a graph that has (Unit)-[:NEXT]->(Unit) structure.
We can use this basic skeleton as the foundation and extend the data architecture to support more advanced features: syntactic analysis and semantic analysis.
This is Part 1 of a series exploring semantic text representation. Future posts will cover syntactic relationships and semantic entity extraction.